Speedtest
Posted on mié 11 noviembre 2015 in Linux • Tagged with experimentos, linux, r
Desde septiembre comencé a medir la velocidad de conexion de mi enlace a internet y he publicado algunos resultados en twitter. Cada vez que publíco algo, me preguntan con qué mido o cual es la metodología que estoy ocupando.
Para no tener que estar repitiendo lo mismo cada vez, en este post voy a detallar el proceso que uso para obtener y procesar las mediciones.
¿Cómo mido mi velocidad de descarga?
Lo más importante es asegurarse que las condiciones de la conexión no cambien por "factores ambientales", por esto no es recomendable usar wifi para realizar las mediciones. Otro punto importante es medir la velocidad de descarga nacional, que es la que los ISP aseguran.
En mi caso, tengo un computador con linux conectado por cable a la red y que está encendido todo el dia. En este computador dejé programada una tarea, mediante un cron que corre cada media hora y descarga un archivo de 10MB
*/30 * * * * wget -O /dev/null http://nacional.grupogtd.com/archivos/10MB.bin 2>&1 | grep '\([0-9,]\+ [KM]B/s\)' >> test-velocidad.txt
Este comando genera un archivo con el siguiente formato
2015-12-17 05:00:04 (3,35 MB/s) - ‘/dev/null’ saved [10485760/10485760]
2015-12-17 05:30:04 (3,99 MB/s) - ‘/dev/null’ saved [10485760/10485760]
2015-12-17 06:00:07 (2,81 MB/s) - ‘/dev/null’ saved [10485760/10485760]
2015-12-17 06:30:05 (3,07 MB/s) - ‘/dev/null’ saved [10485760/10485760]
2015-12-17 07:00:03 (4,76 MB/s) - ‘/dev/null’ saved [10485760/10485760]
2015-12-17 07:30:04 (4,39 MB/s) - ‘/dev/null’ saved [10485760/10485760]
2015-12-17 08:00:10 (1,01 MB/s) - ‘/dev/null’ saved [10485760/10485760]
2015-12-17 08:30:04 (4,04 MB/s) - ‘/dev/null’ saved [10485760/10485760]
2015-12-17 09:00:11 (1,04 MB/s) - ‘/dev/null’ saved [10485760/10485760]
2015-12-17 09:30:04 (3,32 MB/s) - ‘/dev/null’ saved [10485760/10485760]
El formato de este archivo no es muy facil de procesar, por lo que lo transformo a CSV con este comando
awk '{gsub ("\\(","",$3); gsub(",",".",$3); gsub("\\)","",$4); print $1, $2 ",", $3 ",", $4}' test-velocidad.txt > test-velocidad.csv
El archivo resultante queda así
2015-12-17 05:00:04, 3.35, MB/s
2015-12-17 05:30:04, 3.99, MB/s
2015-12-17 06:00:07, 2.81, MB/s
2015-12-17 06:30:05, 3.07, MB/s
2015-12-17 07:00:03, 4.76, MB/s
2015-12-17 07:30:04, 4.39, MB/s
2015-12-17 08:00:10, 1.01, MB/s
2015-12-17 08:30:04, 4.04, MB/s
2015-12-17 09:00:11, 1.04, MB/s
2015-12-17 09:30:04, 3.32, MB/s
Este formato puede ser llevado fácilmente a excel o libreoffice para poder tabularlo o graficarlo. Para estos fines yo utilizo R, que es un lenguage de programación estadística que me permite obtener datos estadísticos básicos, generar gráficos y hacer modelos de predicción con los datos obtenidos.
Conclusiones
En este gráfico se puede ver como se ha comportado la velocidad de descarga durante el tiempo. Cada punto del gráfico representa una descarga del archivo.
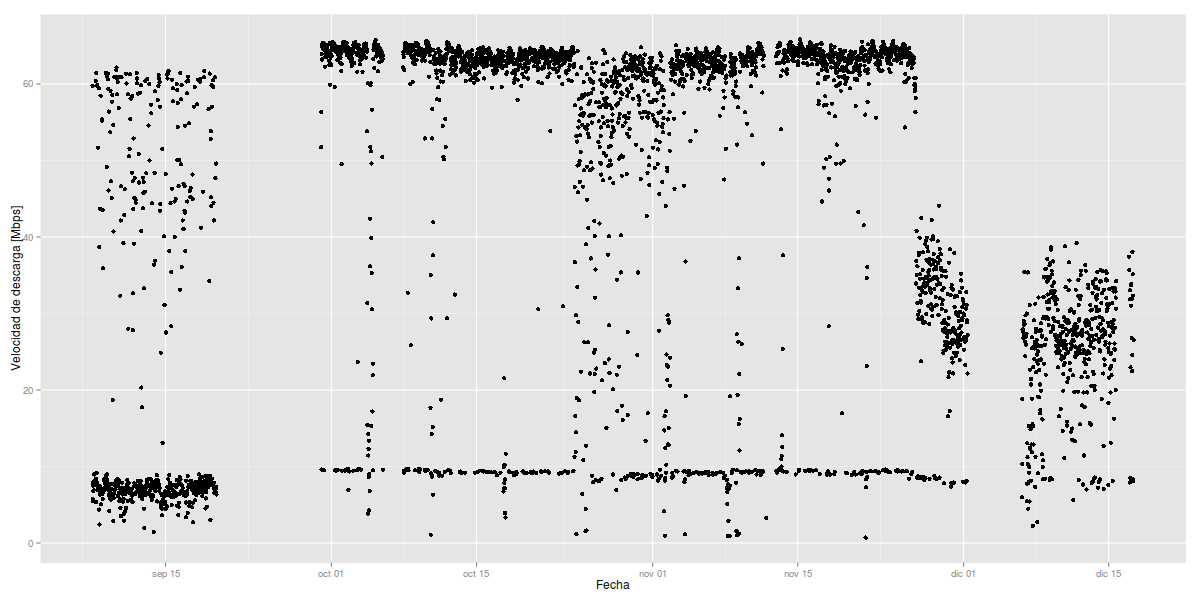
Como se puede ver, mi velocidad de descarga en Septiembre era pésima, mejorando notoriamente en Octubre. Otra cosa que se puede visualizar es que a fines de noviembre, la velocidad de descarga nuevamente ha disminuido.

